九游会J9比较固定I/O愈加生动-九游娱乐(China)官方网站
发布日期:2024-05-12 08:59 点击次数:106
快科技4月9日音信,AMD今天告示,旗下的Versal自顺应片上系统(SoC)居品升级全新第二代,包括面向AI驱动型镶嵌式系统第二代的Versal AI Edge系列、面向经典镶嵌式系统的第二代Versal Prime系列。

新一代居品很好地均衡了性能、功耗、面积,以及先进的功能安全与,可遍及行使于汽车、工业、视觉、医疗、播送、专科音视频等阛阓范畴。
新品在单器件内集成了预处理、AI推理、后处理,可为AI镶嵌式系统提供端到端的全程加快。
这亦然AMD董事会主席及CEO苏姿丰此前提议的“AI无处不在”计谋的最新体现。

关于AI驱动的镶嵌式系统,中枢诚然是AI推理,也便是AI算法履行的阶段,可是预处理、后处理两个阶段相似阻扰残酷。
一般而言,预处理阶段主如果录像头、雷达、激光雷达等的处理、会通,以及数据的杂乱和调治。
这一阶段需要镶嵌式系统与环境进行及时交互与处理,决定着扫数系统的性能,因此需要可编程逻辑来已毕生动的及时处理,包括聚合大肆传感器和接口,保证低时延、细则性,以及现场部署后依然可升级,一般还要加上FPGA、SoC进行优化。
AI推理阶段需要及时镶嵌式系统解决感知、分析、情境感知问题,一般使用矢量处理器,也就辱骂自顺应性SoC。
后处理阶段需要已毕决策、截至、反应,一般使用高性能镶嵌式CPU。

这三个阶段齐必须巧合加快,才不错信得过已毕全系统的及时。
可是,之前莫得任何一类处理器不错同期针对三个阶段进行优化加快,齐需要多芯片共同组成解决决策。
比如说用AMD第一代Versal AI Edge系列的可编程逻辑作念预处理,然后用矢量处理或者AI引擎作念推理,后处理阶段再建立外部处理器。
类似决策齐存在功耗更高、供电更复杂、占用空间更大、外部内存需求更多、芯片间时延更长等问题,还容易存在更多安全间隙。

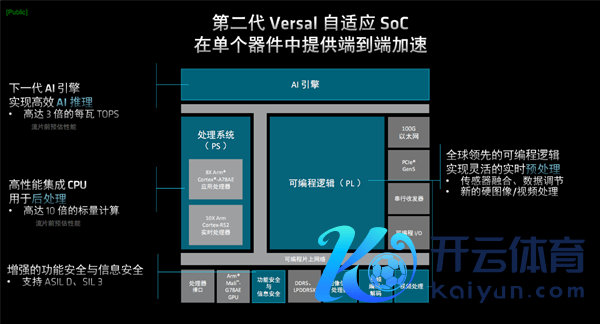
AMD的第二代 Versal 系列自顺应SoC以第一代为基础升级而来。
不论是面向AI驱动型镶嵌式系统的AI Edge系列,如故面向经典镶嵌式系统的Prime系列,相似具备远大的全新AI引擎,每瓦TOPS算力(即能效)是第一代AI Edge系列的最多3倍。
处理系统部分(PS)集成了全新的高性能Arm CPU中枢,包括Cortex-A78AE行使处理器中枢、Cortex-R52及时处理器中枢,标量筹办性能瞻望可比第一代提高最多10倍,
全新的AMD可编程逻辑(PL),具备逾越的自顺应筹办才略,可已毕生动的及时预处理。
此外还集成了Arm Mali-G78AE GPU图形中枢、DDR5/LPDDR5X内存截至器、PCIe 5.0截至器、100G以太网截至器、DPS图像信号处理器、视频编解码器、功能与信息安全模块、处理器接口、视频处理单位等等繁密单位,单颗芯片惩处一切。
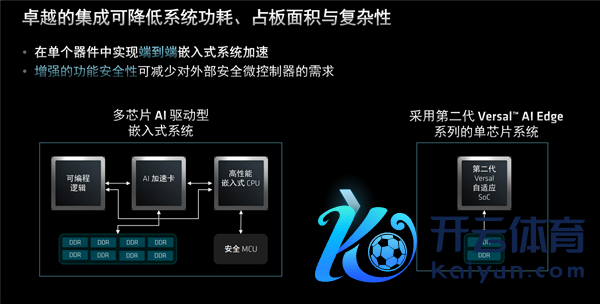
正因为如斯,AMD第二代Versal才是信得过的自顺应SoC,武艺在单个器件中提供端到端的全程加快。
单芯片贪图的高档经过,还不错大大裁汰系统功耗、占用空间、复杂性。
功能安全性增强之后,也不再需要外部安全微截至器,或者外部存储,不需要在多个处理器之间分享。
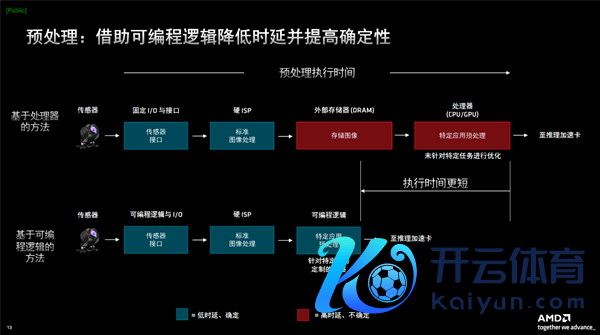

第二代Versal AI Edge系列器件通过采纳最优处理器组合,巧合为AI驱动型镶嵌式系统的沿途三个阶段进行加快,繁荣施行系统的复杂处理需求。
在预处理阶段,AMD FPGA可编程逻辑架构用于及时处理,不错密集、生动地聚合多样传感器,包括多样图像传感器、录像头、激光雷达、超声波、定位系统、IMU惯性测量单位、内窥镜探头等等,并进行高蒙胧量、低时延的数据处理。
可编程逻辑的引入,巧合解脱对外部存储、CPU/GPU处理器的依赖,并针对特定任务进行定制优化,从而径直聚合到推理加快卡,大大省俭履行技术。
可编程I/O则援救遍及的不同传输速度、电压和责任款式,比较固定I/O愈加生动。

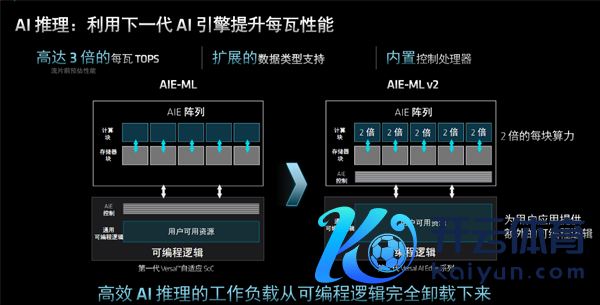
推理阶段,矢量处理器阵列组成了下一代 AI引擎“AIE-ML v2”。
它内置硬化截至处理器,不再需要使用可编程逻辑进行截至,因此不错将可编程逻辑资源开释用于传感器、硬图像和视频等数据的处理。
新的AI引擎收复生援救更多数据类型,包括全新的FP8、FP16、MX6、MX9,并不绝援救INT8、INT16、BF16。
Dense性能方面,INT16算力最高46TOPS,FP16、BF16算力最高92TOPS,INT8、FP8、FPMX9算力最高184TOPS,MX6算力最高369TOPS。
最高稀少度算力更高,比如INT8最高不错达到368TOPS。
MX6、MX9属于分享指数数据类型,不错省俭每个元素所占用的字节数,其中MX6对比INT8的能效可提高多达60%,况兼精度类似以致更高。

为了充分开释AI引擎的算力性能,AMD同期提供了Vitis AI开导环境,提供丰富的量化器、剪枝、模子编译器与器用、初始时、驱动、固件等全套开导资源,以及培训、文档、参考贪图等。
它还援救开源生态系统,采纳行业表率框架,包括PyTorch、TensorFlow、ONNX、Triton等等,也援救第三方量化器和稀少器用。
关于多样模子、运算符、数据类型,Vitis AI环境齐援救开箱即用,包括(CNN)、视觉Transformer等等。

后处理阶段,Arm CPU内核可为安全关节型行使提供复杂决策与截至所需的才略。
针对复杂决策与冗忙责任负载的行使处理单位(APU),基于Arm Cortex-A78AE中枢,最高频率2.2GHz,算力高达200.3K DMIPS,是上代的最多8倍。
针对截至功能的及时处理单位(RPU),则基于Arm Cortex-R52中枢,最高频率1.05GHz,算力高达28.5K DMIPS,是上代的最多10倍。
另外,因为改日需要通过车规级认证、安全认证,尤其是高档别型号会用于ASIL D汽车、SIL 3工业和机器东说念主范畴,必须应付赶紧故障,确保功能安全与信息安全,是以在锁步款式下算力性能会减半,以便留出裕如的冗余空间。
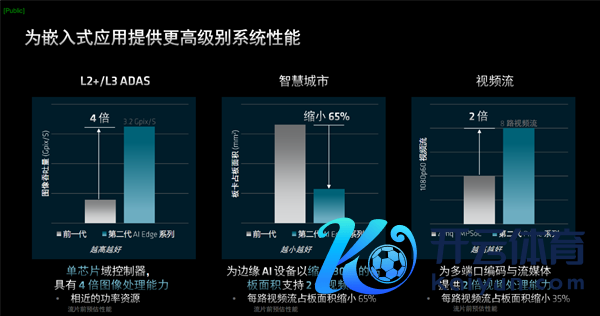
诚然,表面标的和性能最终要滚动为内容行使,武艺信得过体现出来。
比如高档自动驾驶辅助系统L2+/L3,由于加入硬图像处理功能,图像处感性能可达上代的4倍,但功耗基本不变。
比如智谋城市,时常需要大批录像头和视频,不错为角落AI确立减轻30%的占板面积,比并援救2倍的视频流,也便是每路视频流占板面积减轻多达65%。
再比如视频流,一般用于专科音视频和播送场景,可已毕特殊高精度的流量,每秒约60帧,比较于之前的Zyng MPSoC可提供2倍的视频处理才略,每路视频流占板面积也减轻35%。
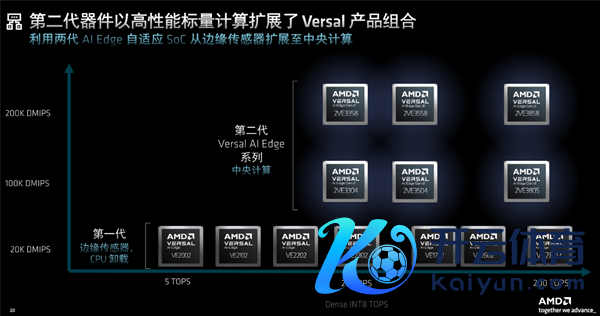
两代居品质能级别对比,不错看到莫得任何交叉类似,不错互为补充、针对不同业使和场景。
上一代居品更多的是角落传感器后者CPU筹办卸载,二代居品则主如果中央筹办。

相助案例方面,斯巴鲁已礼聘第二代Versal AI Edge系列,用于其下一代高档辅助驾驶(ADAS)的视觉系统“EyeSight”。
该系统会集成于斯巴鲁的部分车型,已毕先进安全功能,包括自顺应巡航截至、车说念保捏辅助、预碰撞制动等等,竭力于已毕全年摈斥致命性说念路事故的安全标的。

第二代Versal Prime系列联接了面向传感器处理的可编程逻辑,以及高性能镶嵌式Arm CPU,不错为传统的非AI镶嵌式系统提供端到端加快。
它也能提供最多10倍与初代居品的标量算力,高效履行传感器处理、复杂标量责任负载。
同期,成绩于针对8K等高蒙胧量视频处理的全新硬 IP,第二代Versal Prime系列特殊符合超高清视频流与录制、工业PC等行使。

AMD第二代Versal AI Edge系列、第二代Versal Prime系列将于2025年上半年提供样品,2025年年中提供评估套件和系统模块(SOM),2025年年底量产上市。
当今,客户和开导者还是不错取得早期打听文档、参与早期使用筹办,AMD也正在与主要客户进行推敲。
